Our Cache Made the App Slower. The Redis Mistake I’ll Never Repeat
backend scalability
performance optimization
redis
system performance
backend performance
production debugging
12 min read
1 views

Caching is supposed to be boring. You add it, things get faster, and everyone moves on. That’s the myth.
In our case, adding Redis did improve performance at first. API response times dropped sharply. The team celebrated. A few weeks later, complaints started coming in. Users reported outdated data. Some pages felt slower than before. Support escalations increased.
Nothing was “broken.” That’s what made it dangerous.
Why This Problem Didn’t Show Up Immediately
The cache worked perfectly in isolation. The issue only appeared once real usage patterns emerged.
Traffic was uneven. Some endpoints were hit constantly. Others were hit sporadically. Writes happened less often than reads, but when they did, they mattered.
The system assumed cached data would remain valid long enough to be useful. That assumption was wrong.
The Original Caching Logic
The backend cached API responses aggressively. The goal was to reduce database load and speed up list endpoints.
const cached = await redis.get(key);
if (cached) return JSON.parse(cached);
const data = await fetchFromDB();
await redis.set(key, JSON.stringify(data), "EX", 3600);
return data;On paper, this looked fine. One hour TTL. Simple logic. No complexity.
In production, this created a slow-moving disaster.
Bug Breakdown – Stale Data Is Still Data
The real issue wasn’t correctness alone. It was trust.
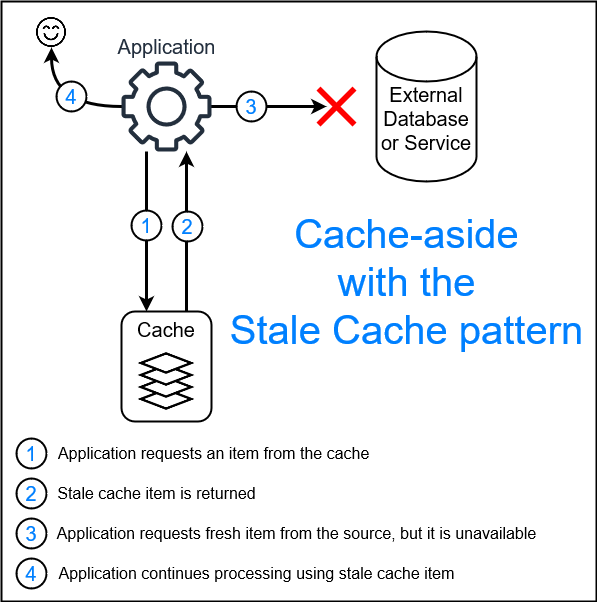
Users saw values that didn’t reflect recent actions. They refreshed repeatedly. That caused cache misses and extra load. Some requests bypassed cache due to key mismatches. Others hit outdated entries.
The system oscillated between fast and slow. Predictability vanished.
Caching doesn’t just affect speed. It affects behavior.
The Root Cause We Missed
The cache key design ignored context.
The same key was used for:
Different filter combinations
Different user scopes
Slightly different query shapes
This caused cache collisions and unnecessary invalidations. Worse, updates didn’t invalidate related keys at all.
The cache wasn’t wrong. It was naïve.
The Fix Was Not “Lower the TTL”
Lowering TTL was the first instinct. It helped briefly. Then load increased again.
The real fix required three changes.
First, cache keys had to reflect access patterns, not endpoints.
Second, invalidation had to be explicit, not time-based guessing.
Third, only read-heavy, low-volatility data deserved caching.
Refactoring the Cache Strategy
Instead of caching entire responses, we cached normalized slices.
const key = `company:${companyId}:orders:page:${page}`;On writes, we invalidated only the affected namespace.
await redis.del(`company:${companyId}:orders:*`);This reduced blast radius and restored predictability.
Another Example:
Anti-Pattern
redis.set(key, data, "EX", 3600);Production-Grade Pattern
redis.set(key, data);
invalidateRelatedKeysOnWrite();Plain explanation
Time-based expiration guesses. Explicit invalidation designs.
Why We Didn’t Cache Everything
We consciously chose not to cache:
Rapidly changing dashboards
User-specific transactional data
Anything tied to real-time decisions
Caching everything increases complexity faster than it increases speed.
This decision aged well as traffic grew.
Cache Invalidation vs Freshness
Perfect cache invalidation doesn’t exist. You choose where to be wrong.
We accepted:
Slightly higher read latency on some endpoints
Lower cache hit rate overall
In exchange, we gained:
Data correctness
Stable performance
Reduced support issues
Speed without trust is useless.
How This Changed Our Backend Discipline
After this incident:
Every cache required an invalidation plan
Cache keys were documented like APIs
Performance tests included stale-data scenarios
Caching stopped being a shortcut and became part of system design.
Business Impact Nobody Expected
Once stale data disappeared:
Refresh storms stopped
Backend load stabilized
Support tickets dropped noticeably
User confidence returned
Performance issues are often behavioral, not technical.
Final Takeaway
Caching is not an optimization layer you sprinkle on top. It is a data consistency contract.
If you can’t explain how and when cached data becomes invalid, you are not optimizing. You are deferring a production incident.
Frequently Asked Questions
Continue Reading

Backend Engineering16 min read
How a Hidden N+1 Query Slowed Our API by 6× and the Exact Steps I Used to Fix It
The API wasn’t crashing. Nothing looked broken. But production response times quietly became six times slower. This is a real-world breakdown of how a hidden N+1 query slipped through reviews, how I proved it in Laravel, and the exact steps that fixed it permanently.
Mar 09, 2026123 views

Backend Engineering15 min read
How I Built an AI-Assisted Log Analysis System to Catch Production Issues Before Users Did
Logs were there. Alerts were there. Incidents still slipped through. This guide explains how I combined traditional logging with AI-driven pattern analysis to proactively detect production issues and reduce firefighting.
Jan 18, 20262 views

Backend Engineering14 min read
Why OFFSET Pagination Broke Our API at Scale (And How Cursor Pagination Fixed It)
Pagination worked fine until traffic and data grew. Then response times spiked quietly. This is the real system-design breakdown of why OFFSET pagination fails in production and how I migrated to cursor-based pagination without breaking clients or SEO.
Jan 16, 20261 views